Setup a foolproof CI with Scrutinizer as a step

Continuous Integration. Wow, that sounds awesome! Indeed it’s one of those loosely-used terms programmers love, alongside “Big Data”, “Code Review” and the likes. But more than being a cool buzzword, a proper CI setup for your development project can go a long way in preventing mistakes from going live on production servers. Continuous Integration is, much like trials, all about reasonable doubt. I reasonably doubt that my code is 100% perfect, best-practice, non-buggy and non-conflicting. I doubt my colleagues’ is. So the solution is for all of us to check every time. Automatically, because we’re lazy.
Continuous Integration means that every time you add something to your codebase, via approved Pull Requests or commits and pushes, your entire code is swept for possible errors. Now, most developers immediately jump to the conclusion that CI is about running unit tests, but that is not the entire truth. CI can be about running various sorts of tests, code quality checks and conformance verifications.
This article will introduce you to Scrutinizer, a tool which I trust will become a staple of your projects from now on. Previously only a PHP CI tool, they have introduced Python and Ruby and plan to support Java and Scala in the future as well. Features include running tests, but where they shine brightest is their analytics part, where repository code is “scrutinized” for possible code smells, adherence to coding standards, unused variables, code repetition, possible bug indicators and so on. My personal preference is to have Scrutinizer as an step in my CI setup, alongside another test-running tool (like CircleCI, CodeShip, Jenkins etc.) and to separate their concerns by having Scrutinizer only run the code analysis part. For the remainder of this article I will assume you understand Git, Django/Python, YAML and basic concepts related to code analysis and best practices. I chose Python for this specific example, but we pride ourselves in being framework-agnostic and enjoy writing about PHP as well.
Setting up Scrutinizer for your repository
Scrutinizer asks you first and foremost to setup a repository to track. This is done in a simple form where you input the repository name, default configuration (which you can later change and tweak) and whether you want tests run as well. For my example, I am only using Scrutinizer for code analysis, so I will leave the box unchecked. I will use my jobeet_py repository (with a new branch called scrutinizer_article ), which I have used for previous articles.
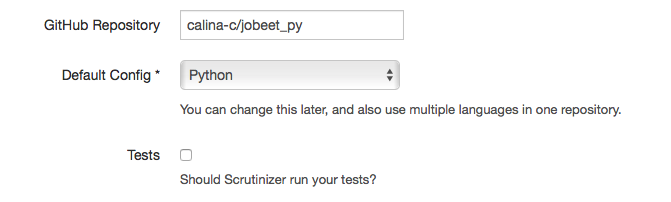
After setting up the repo, a first inspection is automatically scheduled. Unfortunately, our Python repository needs some extra dependencies, so the first inspection’s setup will fail. In the config tab, we add the lines:
build:
environment:
python: 2.7.7
dependencies:
before:
- 'sudo apt-get install -y libmysqlclient-dev'
- 'pip install -r requirements.txt'which instructs Scrutinizer that before running the analysis, it should make sure the version of Python used is our own local one and run some extra commands. Since our project uses MySQL, we install libmysqlclient-dev on the workers and use pip to install further Python dependencies. The Python best practice is to store these in a requirements file which contains names and versions of the libraries used (our requirements.txt).
Checkmark the checks
The next step is to configure the checks which Scrutinizer will make for you. It may be possible that your project upholds a different coding standard than others, so you can obviously configure which elements you want to treat as errors and violations. You can do that either by selecting the desired checkboxes in the “Checks” section of the config, or by directly adding them in the configuration YAML file.
For example, the “Discourage usage of wildcard imports” checkbox corresponds to the following lines in the configuration:
checks:
python:
[...]
imports_wildcard_import: true
[...]For more complex configuration, the YAML entry is allowed to contain children, as is the example of line length. When configuring that code lines do not exceed 80 characters (per PEP-8 Python standard), the configuration can be written as:
checks:
python:
[...]
format_line_too_long:
max_length: '80'
[...]An important thing is to waive checking of special files such as migrations, which are auto-generated and will not adhere to coding rules.
filter:
excluded_paths:
- '*/test/*'
- '*/migrations/*'Running the inspection will now check conformance to your desired list of checks.
Playing “Cops and Robbers” isn’t fun without a robber
Let’s try to shake things up a bit. I will intentionally introduce some errors in my code, in order to check that Scrutinizer really does its job. In views.py :
from jobeet.models import * # to be scrutinized
from jobeet.models import Category # to be scrutinized
"""
This function returns nothing and is called with the wrong
number of arguments, it should be pointed out in Scrutinizer
"""
def do_something(arg1, arg2):
print("Hello")
def index(request):
# This is a comment way too long and I will probably see some errors in Scrutinizer for this :)
signature = 'Unused string' # to be scrutinized
do_something('just_one_arg')
if sgnature: # intentional typo to be scrutinized
pass
return render(request, 'jobeet/index.html', {
'signature': 'C3-PO, Human-Cyborg relations.'
})I commit and push these changes, which prompts Scrutinizer to run an inspection saying 15 issues were introduced. Scrutinizer labels them according to their type and severity and indicates that a Major Bug is:
It seems like a value for argument arg2 is missing in the function call.
while other errors are classified as Coding Standards and Informational:
The usage of wildcard imports like jobeet.models should generally be avoided. This line is too long as per the coding-style (99/80).
Scrutinizer’s utilities not only classify the bugs, but they also track them to the developer who introduced them and the commit which started the problem. It also informs you about code rating, based on number of mistakes, a piece of information you can also flaunt online using a badge… Well, if it’s a good rating anyway.
And it’s true! Had I designed a test for my commit, the test would have caught it. But if I hadn’t, if I had pushed my code into production with a missing function parameter, it would have resulted in users seeing some errors. Depending on the financial significance of my project, this mistake could have costed the company a lot of money and distrust from customers. Remember that we are humans, ergo we are prone to making mistakes. We can always apply best practices and, in the end, revert erroneous changes, but once deployed, the tiniest of errors may prove catastrophic.
Standards matter
Coding Standards are generally viewed as the enemy, since we seldom want to spend precious time reformatting our code. But the overall structure, usability and readability of the code are generally good indicators of the project’s quality. A tool like Scrutinizer can help you detect and solve numerous bugs and give you an objective evaluation of your skills as a developer (team). And, I promise you this: it is better to directly write clean code, than go in and refactor everything when it starts to crumble under its own weight.
Have you used Scrutinizer before? Are you tempted? Let us know how it went. And if you want to read more articles about good CI practices, let us know and we will cover unit tests and functional tests with great pleasure.
We transform challenges into digital experiences
Get in touch to let us know what you’re looking for. Our policy includes 14 days risk-free!
Free project consultation